
이 글을 읽는 독자들께서는 최근 몇 년간 다양한 매체를 통해 ‘문해력’이라는 단어를 가끔 들어보셨을 것이다. 사실 이 단어는 대중들에게 친숙한 단어는 아니었다. 문해력이라는 단어는 주로 아동들의 언어 발달 연구와 관련된 맥락에서 학문적으로 사용되던 용어로, 글(단어)을 읽고 그 의미를 이해할 수 있는 능력을 뜻하는 말이다. 이 단어가 다양한 이유로 대중들에게 자주 노출되게 되었는데, 큰 이슈가 된 이유는 문해력이라는 단어가 ‘논란’을 일으켰기 때문일 것이다. 몇 가지 아주 잘 알려진 예를 소개하자면, ‘심심甚深한 사과’의 심심을 원래의 뜻인 ‘깊고 간절한’으로 이해하지 못하고, ‘하는 일이 없어 지루하고 재미가 없는’ 의 의미로 오해한다든지, 가정통신문에 ‘체험학습 시 중식 제공’이라는 글귀를 보고 한 학부모가 중국 음식 말고 한식으로 주면 안 되냐고, 학교에서 독단적으로 메뉴를 결정하면 안 된다며 학교 측에 항의했다는 일화 등이 있다.
사실 단어의 의미를 몰라서 생기는 오해는 일상다반사이다. 하지만 이것이 논란이 된 것은 한국어를 모국어로 쓰는 사람이 앞서 예로 든 단어의 뜻을 잘 모른다는 것이 말이 되느냐 혹은 모를 수도 있는 것이 아니냐로 온라인 커뮤니티를 중심으로 갑론을박이 이루어졌기 때문이고, 이 논란 때문에 더욱 많은 사람들이 문해력에 대해 관심을 갖게 되었다.1
필자가 문해력 논란의 예시를 이 글의 서두에서 꺼낸 것은 이 논란의 배경이나 원인에 대한 다학문적 분석을 하기 위함도 아니고, 과학적 근거를 바탕으로 양 측 주장 중 한 쪽의 손을 들어주기 위함은 더더욱 아니다. 인간의 언어정보처리를 공부하는 한 사람으로서 그저 이 논란이 반갑기 때문이다. 왜 반갑냐고 물으신다면, 이 논란으로 인해 모국어 문해력의 개인차에 관한 중요성을 많은 사람들이 인지했기 때문이다. ‘심심한 사과’의 심심甚深의 정확한 뜻을 알고 있었던 사람이 과연 얼마나 될까? 부끄러운 이야기이지만 필자 역시도 이 단어를 ‘진심이 담긴’ 정도의 뜻으로 알고 있었지, 정확히 어떤 한자로 구성된 단어인지는 이 논란 전에는 알지 못했다. 즉 이 단어의 뜻을 정확하게 알고 있는 사람들부터 필자와 같이 대략적인 의미만 파악하고 있는 사람들, 그리고 이 단어의 의미를 ‘지루하고 재미없는’으로만 알고 있는 사람들까지, 비록 한국어를 모국어로 사용하고 있는 성인이라고 하더라도 어휘 지식의 측면에서 큰 개인차가 존재함을 보여주는 흥미로운 예시라는 것이다. 우리는 모두 자신의 모국어를 능숙하게 사용할 수 있다고 느끼고 있지만, 언어 능숙도의, 더 좁혀서 문해력의 개인차는 분명 존재한다.
이러한 예시가 무척 흥미롭긴 하지만, 학문적 관점에서 일반화하기는 힘들다. 어찌 보면 그저 재미난 일화에 지나지 않을 수도 있지 않을까? 모국어를 능숙하게 사용하는 성인들도 글을 읽고 이해하는 능력에서 그렇게 큰 차이가 날까? 아마도 대학수학능력시험의 언어영역 문제를 풀어보신 분들이라면 이 질문에 쉽게 답하실 수 있을 것으로 생각한다. 모국어를 능숙하게 말하고 이해할 수 있는 사람들이라도 문해력은 분명한 차이가 난다. 이러한 차이가 나는 이유는 정말로 다양하다. 어휘력의 문제일 수도 있고, 문법 정보처리의 효율성과 정확성이 문제가 될 수도 있으며, 작업기억이나 정보처리속도와 같은 더 일반적인 인지 능력이 원인일 수도 있다. 물론 가정 환경이나 교육 시스템 등 개인의 범위를 벗어난 영역도 분명 일정 부분 이러한 문해력의 개인차에 영향을 줄 것이다. 이러한 원인들에 관해 종합적으로 이야기하는 것은 지면의 한계로 인하여 접어두고, 이 글에서는 개인의 언어 능력, 그 중에서도 어휘력과 독서 경험이라는 측면에서 모국어 문해력의 개인차에 관해 살펴보도록 하자.
어휘력의 개인차
성인들의 문해력을 구성하는 성분에는 여러 가지가 있겠으나, 이 중 어휘력은 정말 빼 놓을 수 없다. 앞에서 예로 들었던 ‘심심한’이나 ‘중식’과 같은 단어로 인해 생긴 문해력 논란의 예도 결국은 어휘력의 문제이다. 어휘력의 차이가 문해력의 차이를 만드는 중요한 원인임은 부인할 수 없는 사실이다. 예를 들어 10개의 단어로 구성된 하나의 문장에 그 뜻을 잘 모르는 단어가 5개가 넘는다면 그 문장을 제대로 이해한다는 것은 어불성설이다. 따라서 어휘력의 개인차를 정확하게 측정할 수 있다면 문해력의 개인차가 나타나는 이유를 상당부분 설명할 수 있을 것이다. 인간의 언어 정보처리를 연구하는 언어심리학자들도 어휘력을 측정하기 위한 과학적으로 타당하고 신뢰도가 높은 도구를 사용하여 어휘력을 측정하고자 많은 노력을 하고 있다. 그런데 여기서 아주 흥미롭지만, 한국어를 연구하는 학자들에게는 곤혹스러운 개별 언어의 특성이 작동한다. 예를 들어 영어는 어휘력의 개인차를 측정하는 도구를 제작하는 것이 상대적으로 쉽다. 가장 간단한 방법은 특정 단어 목록을 정확하게 읽을 수 있는지를 측정하는 것이다. 미국과 캐나다에서 주로 사용하는 과제 중 National Adult Reading TestNART라는 과제가 있는데, 북미 영어를 모국어로 사용하는 성인들에게 적용 가능한 과제이다. 50개의 단어로 구성된 하나의 목록을 주고, 이 단어들을 정확하게 소리 내어 읽는 과제이다. 단어의 뜻이 무엇인지, 어떤 맥락에서 사용되는지 등에 대해 자세히 물을 필요도 없다. 그냥 읽기만 하면 된다. 그런데 이 과제를 한국어를 모국어로 사용하는 사람들의 관점에서 보면 머리를 갸우뚱하게 만든다. 단지 읽을 수 있다는 것이 그 단어의 뜻을 정확히 이해하고 있다는 것을 의미하지는 않을텐데 말이다. 하지만 NART는 북미권에서 상당히 많이 사용되는 과제로서, 면밀하게 측정된 언어지능검사의 점수와도 큰 상관관계가 있다고 알려져 있고, 뇌손상 환자들의 손상 전 지능을 효과적으로 예측하는 도구로도 많이 사용되고 있다(Blair & Spreen, 1989; Grober et al., 1991). 어떻게 이런 일이 가능할까? 그것은 영어가 가지고 있는 문자와 발음의 대응 불규칙성 때문이다. 영어는 하나의 알파벳이 대응되는 소리가 여러 개다. 필자가 근무하는 대학의 영문 약자는 GIST인데, 이를 읽을 때는 지스트로 읽는다. 하지만 이것을 꼭 지스트로 읽을 필요는 없다. 이 단어를 처음 보는 사람들은 기스트로 읽을 수도 있을 것이다. 실제로 필자가 지스트를 잘 모르는 분들과 대화를 하다보면 광주과학기술원의 영문명을 ‘기스트’라고 하시는 경우가 종종 있다. 영어는 이와 같이 알파벳과 소리의 대응이 일대일로 이루어지지 않기 때문에 대응이 불규칙한 영어 단어를 정확하게 읽을 수 있다는 것은, 그 단어의 뜻을 따로 물어보지 않아도 그 뜻을 알고 있다고 생각해도 큰 무리가 없다는 것을 의미한다. 그래서 영어의 어휘력을 측정하는 과제들은 이러한 단어 읽기 형태의 과제들이 많다. 연구에 사용하기도 간단하고, 시간도 많이 걸리지 않을 뿐만 아니라 타당도 역시 높다. 하지만 한국어는 다르다. 한국어는 철자와 발음의 대응이 상당히 일관적이고 규칙적이다. 물론 ‘지스트’의 첫 음절의 /ㅈ/은 ‘낮’과 같은 단어처럼 음절의 종성 위치에 올 때는 발음이 달라지지만, 이것도 상당히 쉬운 규칙이 적용되어 금방 배울 수 있다. 그래서 한국어는 모국어를 능숙하게 사용하는 성인들의 어휘력을 측정하는 과제를 만들기가 여간 어려운 것이 아니다.
한국어를 능숙하게 사용하는 성인들을 대상으로 하는 과학적으로 타당하고 신뢰도가 높은 어휘력 과제를 제작하기 위해서는 상당히 많은 노력이 필요하다. 또한 이런 과제가 개발된다 하더라도 실제로 연구 현장에서 사용되기 위해서는 시간이 너무 오래 걸리면 안 되고 간편해야 한다. 이러한 맥락에서 최근에 개발된 한국어 어휘력 측정 과제가 있는데, 2음절 초성과제이다. 이 과제는 대중들에게 많이 알려진 초성 게임과 매우 유사한 과제이다. 예를 들어 ‘ㅅㄱ’이라는 초성 글자를 제시하고 이 두 개의 초성으로 시작하는 2음절 단어를 1분 동안 최대한 많이 산출하는 것이다. 독자 여러분도 한 번 해보시기 바란다. 사과, 수고, 소고, 서가 …. 몇 개의 단어를 1분 동안 산출해 낼 수 있을까? 참고로 표준국어대사전에 표제어로 등록된 단어 중, ‘ㅅㄱ’을 초성으로 갖는 2음절 명사의 개수는 2000개가 넘는다. 대학생들을 대상으로 이 과제를 사용한 최근 연구 결과에 따르면, ‘ㅅㄱ’라는 초성을 제시했을 때 1분간 평균 11개의 단어를 산출할 수 있었다(Park & Choi, 2024). 더 중요한 것은, 이 과제의 수행 결과, 상당한 개인차가 존재했다는 것이다(그림 1 참조). 참가자들은 모두 모국어를 능숙하게 구사하며 모국어로 된 글을 잘 이해하는 대학생들이었음에도 불구하고, 이들이 가진 어휘의 양을 측정하는 정말 간단한 과제에서도 분명한 개인차가 나타났다는 점은 매우 흥미롭다.
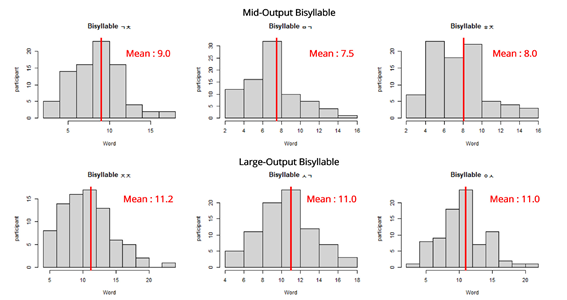
그리고 추가 분석 결과, 2음절 초성과제에서 나타난 개인차는 문장 읽기 시간에서 나타나는 개인차를 잘 설명하는 변수였다. 즉 2음절 초성과제에서 더 많은 단어를 산출한 사람들은 문장을 더 빨리 읽어낼 수 있었다. 물론 문장을 빨리 읽는 것이 문해력이 좋다거나 문장에 대한 이해를 더 잘했다는 것을 직접적으로 말해주지는 않는다. 하지만 이 연구에서 문장을 읽은 뒤, 그 문장을 제대로 읽었는지를 확인했음을 고려할 때, 2음절 초성과제에서 나타난 어휘력의 차이가 문장이 나타내는 의미를 이해하는 속도의 차이를 야기하는 하나의 중요한 원인임을 시사하는 결과임은 분명하다.
2음절 초성과제가 어휘력의 개인차를 측정할 수 있는 쉽고 유용한 과제임을 시사하는 것은 분명하지만, 아직 연구할 문제가 많이 남아 있다. 예를 들어 이러한 개인차가 나타나는 원인이 어휘력 때문이 아니라 집행 통제 기능과 같은 일반 인지 능력의 차이 때문이라는 주장도 제기되고 있다. 2음절 초성과제와 관련하여 향후 어떤 연구 결과가 더 축적될지 귀추가 주목된다.
그렇다면 어휘력이 좋다는 것이 어떻게 문해력과 관계가 있는 것일까? 우리가 단어를 안다라는 의미를 깊이 생각해보면 어휘력과 문해력이 어떻게 관련되는가를 대략적으로는 이해할 수 있다. ‘심심한’이라는 단어의 예를 들어보자. 우리가 이 단어를 안다는 것은 그저 이 문자기호가 무슨 뜻을 가지고 있는가를 말하는 것을 넘어선다. 어떤 발음을 가지고 있고, 이 단어와 함께 나오는 단어들은 무엇이고, 비슷한 뜻을 가진 단어는 어떤 것들이고, 이 단어가 사용되는 문법적 맥락은 어떠하고, 어떤 상황에서 이 단어가 사용되는가를 안다는 것을 의미한다. ‘심심한’과 같은 단어는 두 가지 이상의 의미를 가지고 있으므로 각각의 의미에 대하여 위와 같은 깊은 수준의 정보처리가 아주 빠른 속도로, 그리고 맥락 상 유연하게 일어나야 한다. 우리가 글을 읽을 때 새로운 단어가 머릿속에 계속 빠른 속도로 입력된다는 점을 고려한다면, 즉 기억의 부담이 가중되기 때문에 각각의 단어를 빠르고 효율적으로 이해하는 것은 문해력의 초석이라 해도 과언이 아니다. 피츠버그 대학의 찰스 퍼페티Charles Perfetti교수는 이를 어휘 품질 가설Lexical quality hypothesis이라 명명하며, 문해력에 있어서 정확하고 유연한 어휘 지식의 중요성을 이야기했다(Perfetti, 2007). 즉 우리가 단어를 안다는 것은 그 단어의 철자, 음운, 문법, 및 의미 정보의 깊은 수준까지 정확히 알고 이를 유연하게 적용하는 것을 의미한다. 이러한 깊은 수준의 정보처리 속도와 정확성은 연령이나 언어 경험에 따라 큰 차이가 나타날 수 있으므로 모국어를 능숙하게 구사하는 성인들에게서도 큰 차이가 나타날 수 있고, 이는 문해력의 개인차의 주요한 원인이 될 수 있다. 그렇다면 언어 경험의 개인차에 관해 조금 더 살펴보도록 하자.
독서 경험(인쇄물에 대한 노출 정도)의 개인차
2음절 초성과제가 어휘력을 간편하고 효과적으로 측정할 수 있는 좋은 도구가 될 수 있음을 보았지만, 시간의 압박이 있는 과제이고, 실제 언어 능력뿐만 아니라 일반 인지 능력의 관여가 분명히 있을 수 있는 과제이다. 실험실에서 쉽게 사용 가능하면서도 언어 경험의 개인차를 효과적으로 측정할 수 있는 과제로 또 한 가지 소개할 것은 저자인식검사Author Recognition Test이다. 이 과제는 토론토 대학의 교수이자 저명한 인지과학자인 키스 스타노비치Keith Stanovich2가 개발하였다(Stanovich & West, 1989). 이 과제 역시 간단하다. 한 장의 종이에 사람 이름들이 적혀 있다. 해야 하는 일은 그 이름들 중 책을 쓴 작가들을 골라내는 것이다. 진짜 작가를 제대로 골라내면 작가 당 1점을 얻고, 작가가 아닌 이름을 골라내면 가짜 작가 당 1점을 잃는다. 이 과제의 논리는 이렇다. 인쇄물에 대한 노출 정도가 높을수록, 혹은 독서 경험이 많을수록 더 많은 작가의 이름을 알고 있을 가능성이 클 것이고, 따라서 작가의 이름을 정확하게 골라낼 수 있는 사람은 책을 많이 읽는 사람이라는 것이다. 실제로 저자인식검사를 통해 측정한 인쇄물에 대한 노출 정도와 전반적 읽기 이해도 및 다양한 언어 능력의 관계를 살펴본 99개의 경험 연구를 종합적으로 분석한 메타 연구 결과에 따르면 저자인식검사와 다양한 언어 능숙도의 개인차의 상관관계는 유치원생이나 초등학생들뿐만 아니라 대학생이나 대학원생들과 같은 성인들을 대상으로 한 연구에서도 분명하게, 오히려 더욱 강하게 나타났다(Mol & Bus, 2011). 그리고 영어뿐만 아니라 한국어를 모국어로 사용하는 성인들에게도 유사한 경향성이 나타났다(Kim et al., 2021; Lee et al., 2019).
독서 경험의 개인차가 구체적으로 성인들의 모국어 정보처리의 어떤 측면에 영향을 주는가를 밝히는 것은 상당히 의미 있는 연구주제일 것이다. 문제는 인간의 독서 경험 자체를 실험적으로 조작manipulation하는 것이 불가능하기 때문에 인과적인 실험연구를 수행하기가 쉽지 않다. 이러한 연구를 위해 만약 참가자들에게 한 10년 동안 책을 전혀 읽지 못하게 한다면 학문의 발전을 위해 과감하게 이 연구에 본인이 참여하거나, 자녀들을 참여하게 하실 부모님들이 몇 분이나 계실까? 계신다고 해도 이러한 연구 계획서는 생명윤리심의위원회에서 연구 수행을 허락하지 않을 가능성이 높다. 실험 연구를 직접 수행하는 일은 쉽지 않겠지만, 기존의 상관 연구 결과를 토대로 합리적인 추론을 해 볼 수는 있을 것이다. 특히 어휘력의 관점에서 생각해보자. 아직 글을 읽지 못하는 어린 나이 때부터 부모님과 책을 많이 읽는 아이들은 그렇지 못한 아이들에 비해 높은 수준의 어휘력을 가질 가능성이 크다. 어휘력이 신장됨에 따라 이 아이들은 더 높은 수준의 책을 읽을 수 있게 되고, 또 어휘력은 더 증가한다. 반대의 경우도 마찬가지이다. 어렸을 때 책을 많이 읽지 않으면 어휘력이 신장되기 어렵고, 어휘력이 낮은 상태로 나이를 먹으면서 읽어내야 할 독서 자료가 어려워지면서 글의 이해도가 떨어지고, 이는 글을 읽는 것을 더 어렵게 만든다. 이렇게 계속 책을 읽지 않으면 어휘력은 또래집단에 비해 더 떨어지게 된다. 이러한 독서 경험의 차이에 따라 발생하는 어휘력의 차이는 나이가 들면서 점점 더 심화된다. 따라서 분명 성인이 되어 모국어를 능숙하게 사용할 수 있음에도 불구하고 어휘력의 개인차가 나타나게 되고, 이에 기인한 문해력의 개인차 역시 더 분명해지는 것이다. 스타노비치 교수는 이러한 현상을 마태 효과Matthew effect3 라고 명명했는데, 이는 우리가 흔히 쓰는 표현으로 ‘부익부 빈익빈’의 뜻과 유사하다. 책을 많이 읽는 사람이 더 많은 어휘를 알게 되고, 어휘력이 풍부한 사람은 더 높은 수준의 책을 읽게 되는 사이클이 반복된다. 이런 방식의 상호 인과reciprocal causation적 관계는 저자인식검사를 통해 측정된 독서 경험이 왜 다양한 언어 능숙도 측정치와 강한 상관관계가 나타나는가를 설명해준다.
문해력을 높이기 위한 뻔한 방법
우리는 이 글을 통해 어휘력의 관점에서 왜 문해력의 개인차가 모국어를 능숙하게 구사하는 성인들에게서도 나타날 수 있는가를 알아보았다. 그리고 연구 현장에서 효율적으로 어휘력을 측정할 수 있는 도구들에 대해서도 살펴보았다. 이러한 도구를 사용한 연구 결과에 따르면 문해력의 개인차는 모국어를 배우는 과정에 있는 아동들에게서만 나타나는 것이 아니다. 성인들에게 오히려 개인차의 정도가 더 심화될 수도 있다. 그러면 이제 어떻게 해야 할까? 필자가 이 글에서 저명한 학자들의 이름을 들먹이며, 과학적 연구 결과를 소개하며, 뭔가 대단한 것이 있을 것이라는 기대를 품게 만들었다면, 독자들께는 사과의 말씀을 먼저 올린다. 너무나 뻔한, 누구나 할 수 있는 대답밖에 드릴 수 없어서 (이번엔) 심심한 사과를 드린다. 책을 읽자. 구체적으로 무슨 책을 어떤 방식으로 읽어야 하는가는 나중 문제이다. 문해력 향상의 가장 근본적인 방법은 많이 읽는 것이다. 얼마 전 10월에 필자는 초등학생들을 대상으로 연구를 수행하기 위해 3주간 주말에 국립어린이청소년도서관에 방문하였다. 뿌듯했던 점은 많은 부모님들께서 아이들을 데리고 도서관에 오셔서 함께 책을 읽는 모습을 하루 종일 목격했다는 것이다. 이 아이들을 보면서 마태 효과의 긍정적 사이클이 돌아가는 상상을 하는 일은 정말 행복한 경험이었다. 내 부모님은 함께 책을 읽어주시지도 못했고, 이미 벌써 다 자라서 이번 생은 망했다고 생각하시는 독자분들이 계실는지도 모르겠다. 늦지 않았다고 생각한다. 이번 주말 사시는 곳에서 가장 가까운 도서관이나 서점에 가서 서가를 둘러보시는 것부터 시작이다. 안 그래도 요즘 노벨 문학상 수상자를 배출한 국가의 국민이라는 것에 자부심을 느끼고 있는데, 깊어가는 가을, 겨울이 오기 전에 정말 재미난 소설 한 권씩 읽어보며 성인 문해력 격차 해소에 일조하는 것은 어떨까?
참고문헌
- Blair, J. R., & Spreen, O. (1989). Predicting Premorbid IQ: A revision of the National Adult Reading Test. Clinical Neuropsychologist, 3(2), 129-136.
- Grober, E., Sliwinsk, M., & Korey, S. R. (1991). Development and validation of a model for estimating premorbid verbal intelligence in the elderly. Journal of Clinical and Experimental Neuropsychology, 13(6), 933-949.
- Kim, D., Lowder, M. W., & Choi, W. (2021). Effects of print exposure on an online lexical decision task: A direct replication using a web-based experimental procedure. Frontiers in Psychology, 12, 710663.
- Lee, H., Seong, E., Choi, W., & Lowder, M. W. (2019). Development and assessment of the Korean Author Recognition Test. Quarterly Journal of Experimental Psychology, 72(7), 1837-1846.
- Mol, S. E., & Bus, A. G. (2011). To read or not to read: a meta-analysis of print exposure from infancy to early adulthood. Psychological Bulletin, 137(2), 267-296.
- Perfetti, C. (2007). Reading ability: Lexical quality to comprehension. Scientific Studies of Reading, 11(4), 357-383.
- Stanovich, K. E., & West, R. F. (1989). Exposure to print and orthographic processing. Reading Research Quarterly, 24(4), 402-433.


